记录下python3+中,如何解析url,获取想要的信息过程, 首先看下url的构造,基本结构如下

我们主要借助的是 urlparse 来实现参数解析
1. url初步解析
第一步,将url按照上面的进行分模块
1 | from urllib import parse |
输出如下

按照官方对于 urlparse 方法的说明
Parse a URL into six components, returning a 6-tuple. This corresponds to the general structure of a URL: scheme://netloc/path;parameters?query#fragment. Each tuple item is a string, possibly empty. The components are not broken up in smaller parts
简单来讲,就是将url拆分如下:
1 | scheme://netloc/path;parameters?query#fragment |
具体对应关系如下,每项都是String字符串
- scheme: https
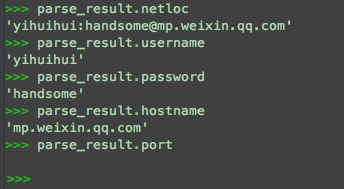
- netloc: yihuihui:handsome@mp.weixin.qq.com
- path: /s/eFvTsAlDddL_Vq9hE3QbjQ
- params: ‘’
- query: user=一灰灰&age=18&cnt=1,2,3&_time=1552639827
- fragment: page
2. netloc 解析
从上面的描述知道,netloc由四部分组成,username, password, hostname, port
上面解析返回的对象已经会帮我们解析好,直接即可
1 | user = parse_result.username |
需要注意的是port返回的是整形,如果url中没有显示加上,则返回空,即默认80端口
3. 请求参数解析
另外一个值得我们说到的就是url参数的解析了,这个参数为query而不是params(也不太明白为什么会有这个存在…)
前面已说到,query返回的是字符串,和我们希望的k.v不太契合,因此可以使用parse_qs
1 | query = parse_result.query |
从输出可以知道,两个方法的区别在于返回的结果类型不同

相关文档
II. 其他
1. 一灰灰Blog: https://liuyueyi.github.io/hexblog
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,已上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
3. 扫描关注
一灰灰blog

知识星球