ElasticSearch 基本使用姿势,如常见的
- 添加文档
- 常见的查询姿势
- 修改/删除文档
1. 添加文档
首次添加文档时,若索引不存在会自动创建; 借助kibana的dev-tools来实现es的交互
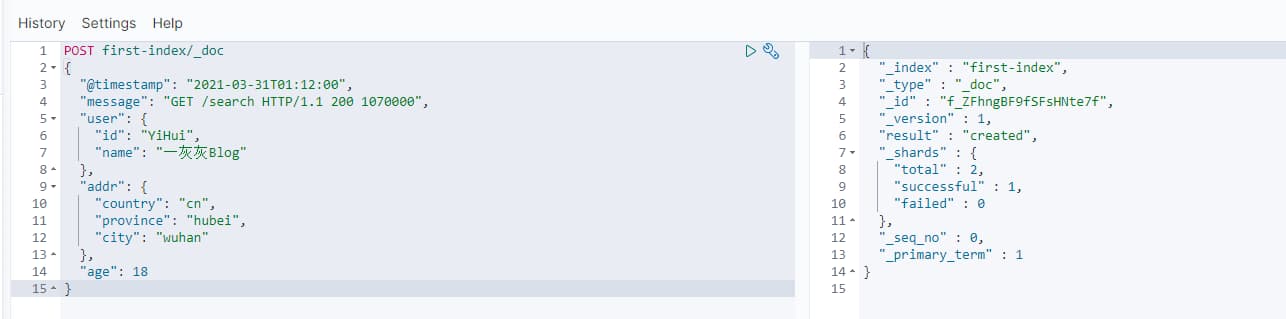
1 | POST first-index/_doc |
当然也可以直接使用http进行交互,下面的方式和上面等价(后面都使用kibanan进行交互,更直观一点)
1 | curl -X POST 'http://localhost:9200/first-index/_doc?pretty' -H 'Content-Type: application/json' -d ' |
2. 查询文档
2.0 kibana配置并查询
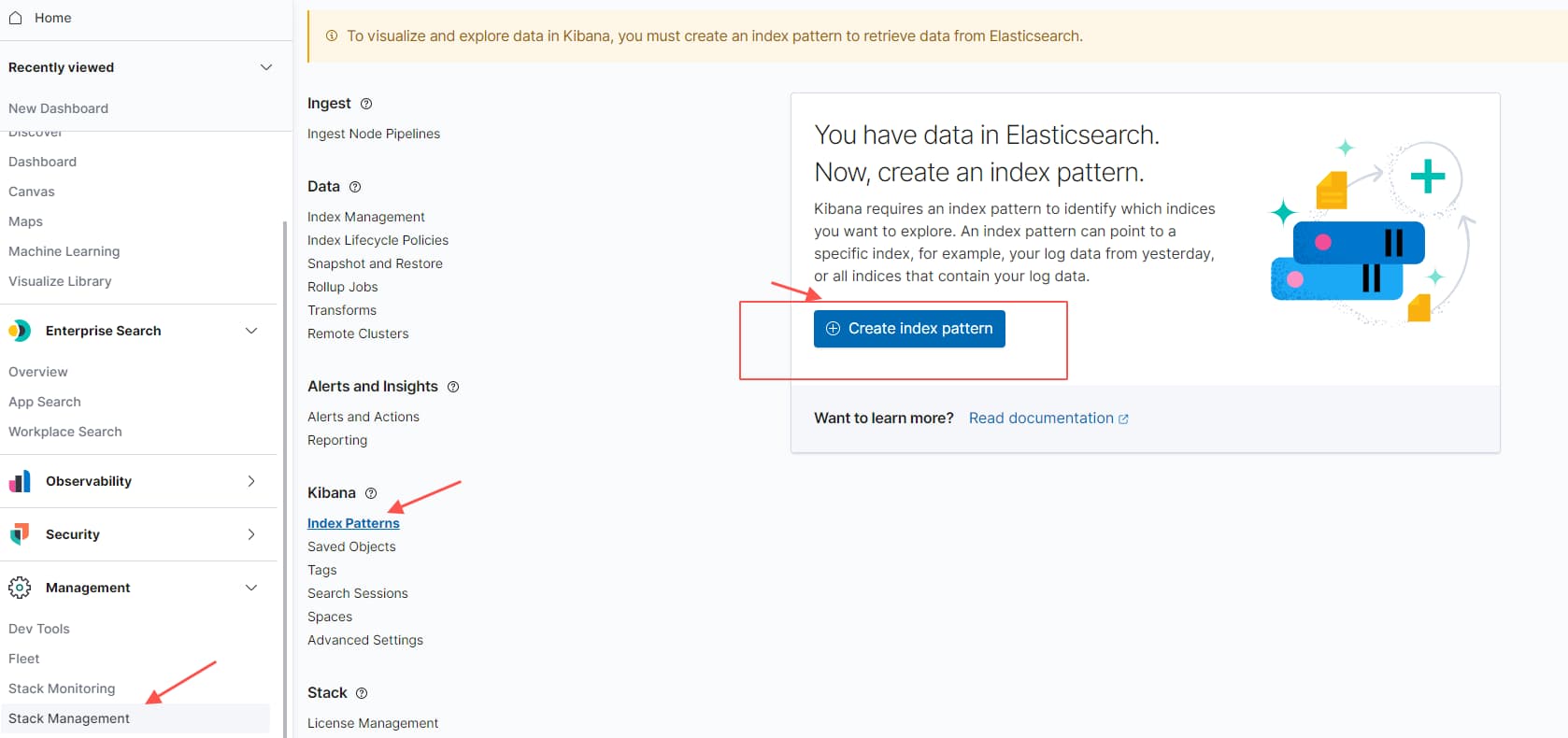
除了基础的查询语法之外,直接使用kibana进行查询,对于使用方而言,门槛最低;首先配置上面的es索引
- Management -> Stack Management -> Kiabana Index Patterns
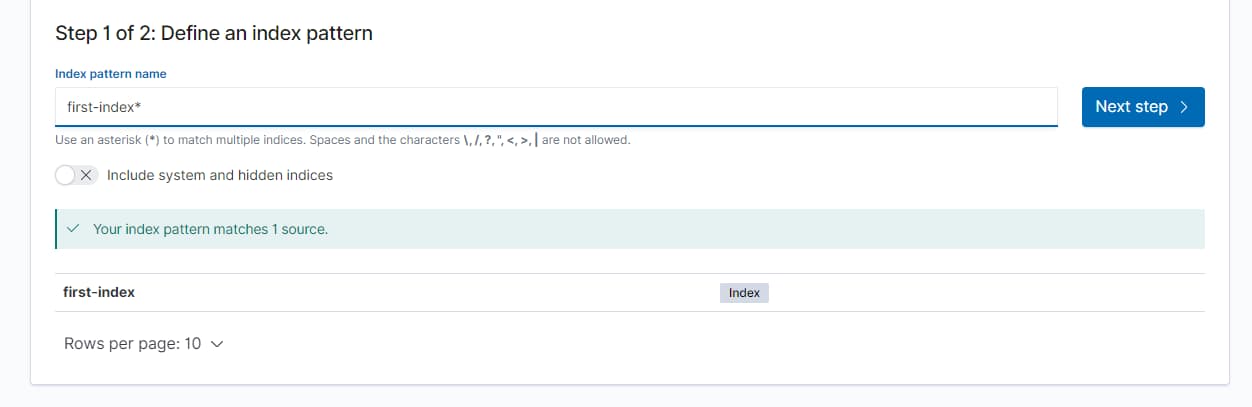
- index pattern name
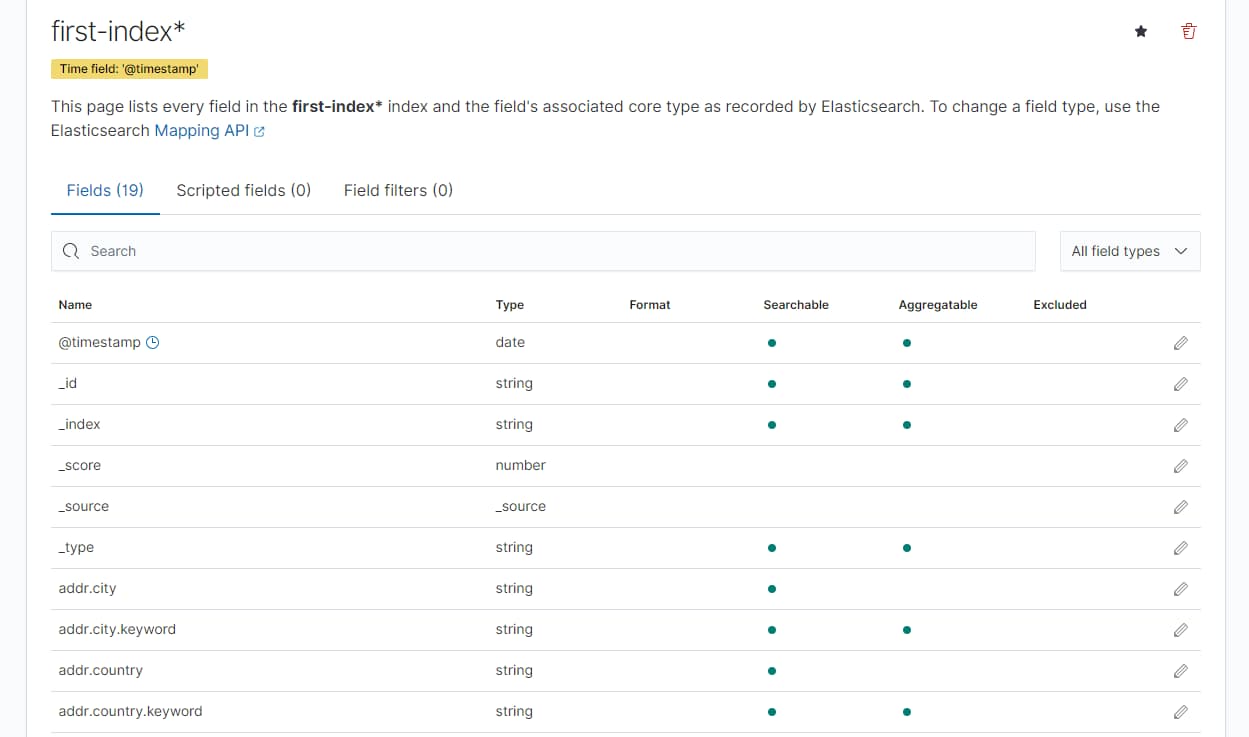
- 时间字段,选择
@timestamp这个与实际的文档中的field有关

接下来进入Discover 进行查询
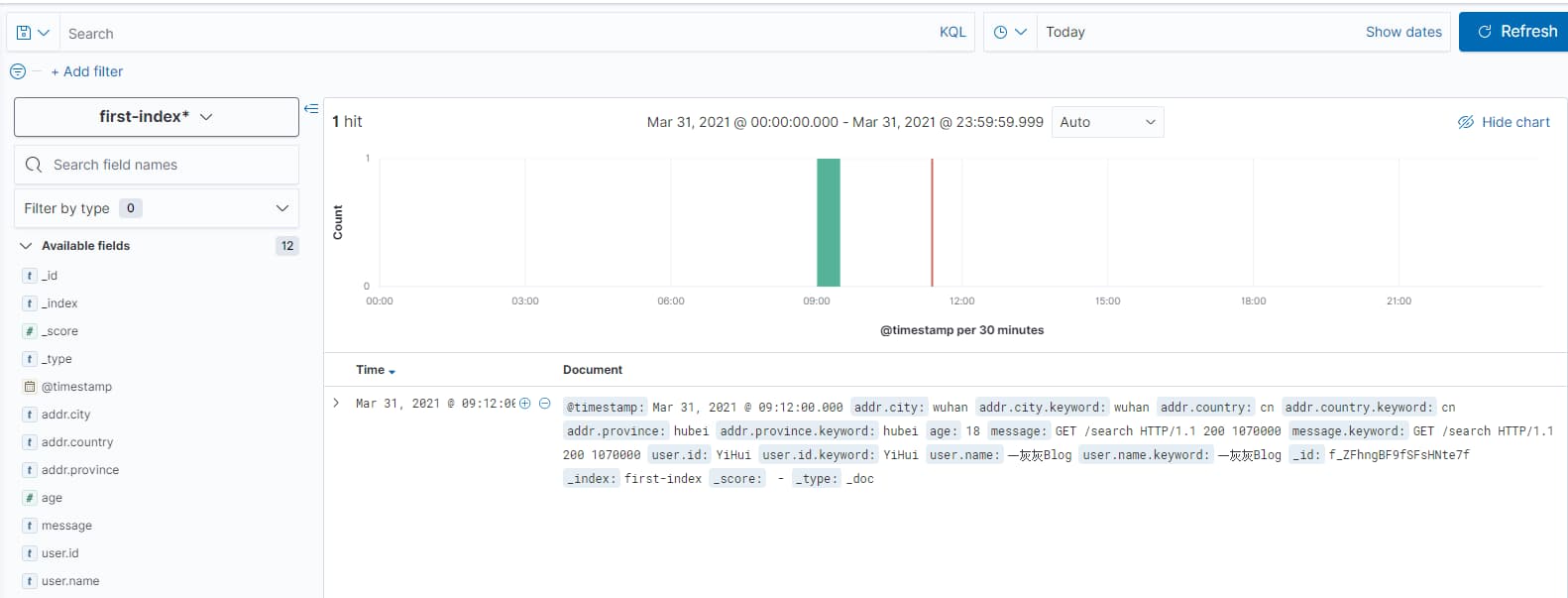
比如字段查询
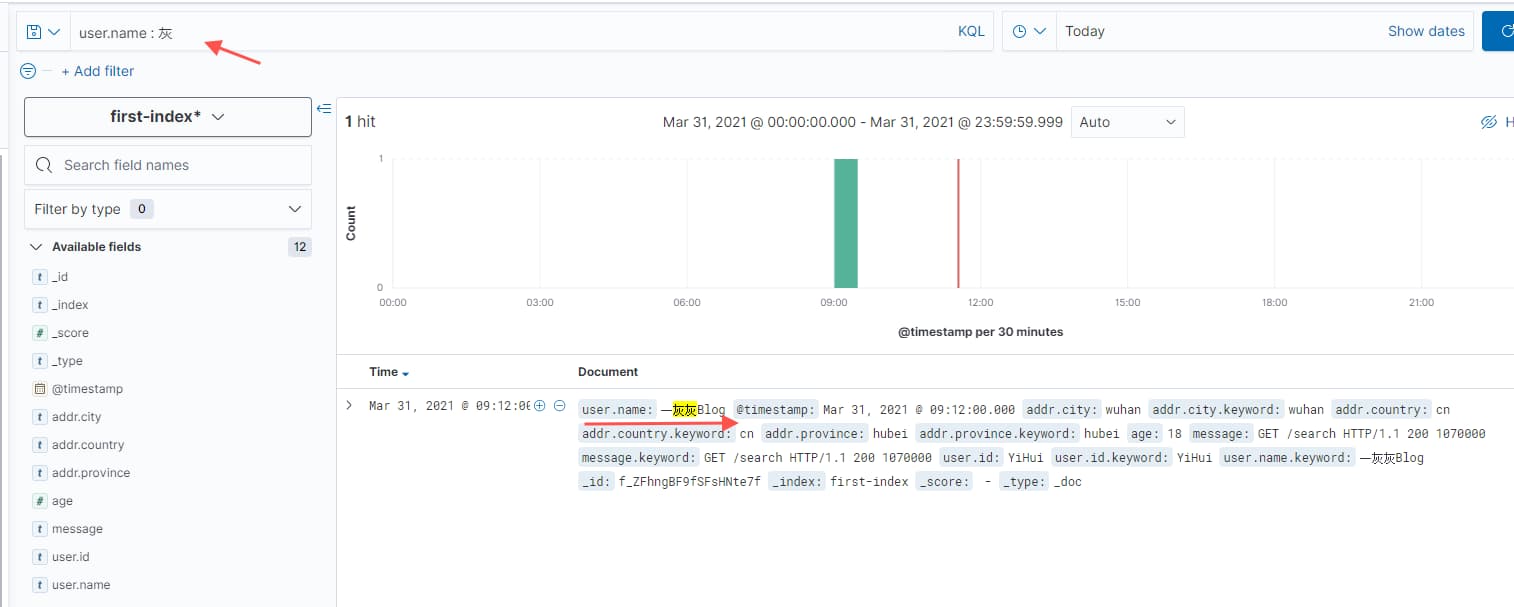
2.1 查询所有
不加任何匹配,捞出文档(当数据量很多时,当然也不会真的全部返回,也是会做分页的)
1 | GET my-index/_search |
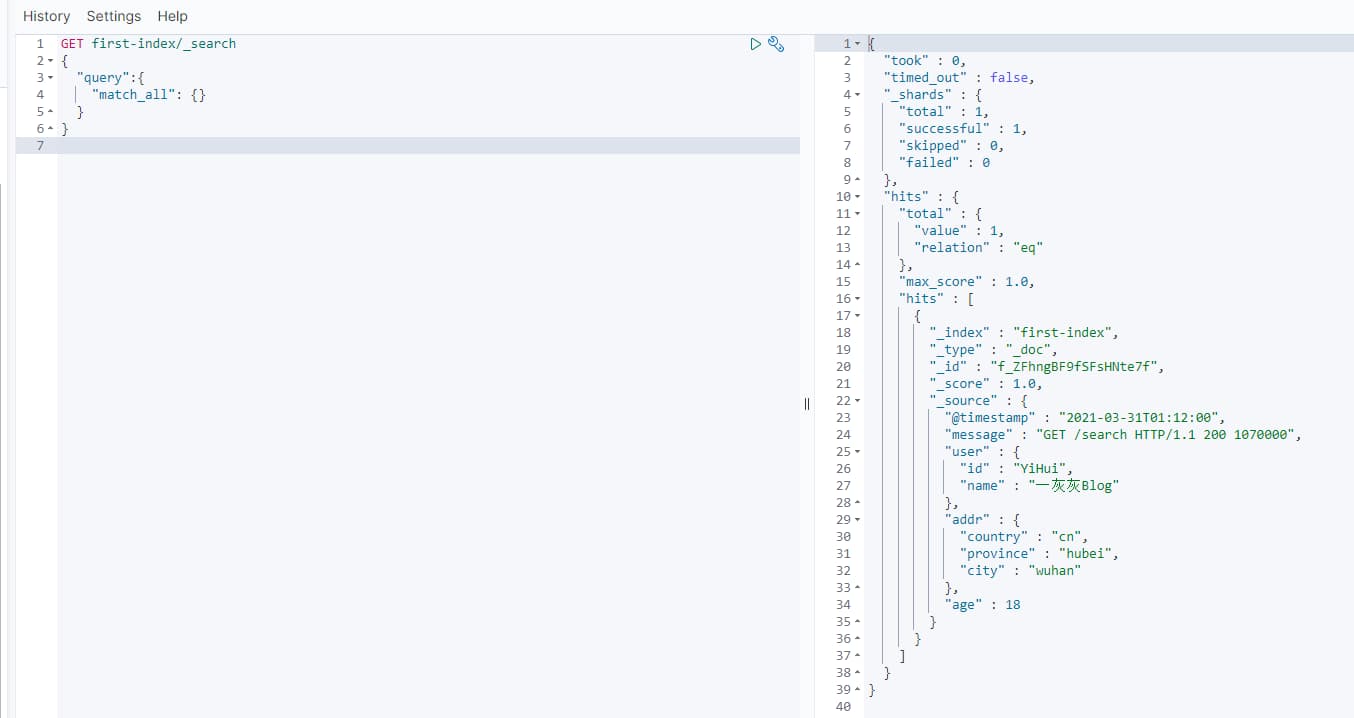
2.2 term精确匹配
根据field进行value匹配,忽略大小写;
查询语法,形如: `{“query”: {“term”: {“成员名”: {“value”: “查询值”}}}}
query,term,value三个key为固定值成员名: 为待查询的成员查询值: 需要匹配的值
(说明:后面语法中,中文的都是需要替换的,英文的为固定值)
1 | GET first-index/_search |
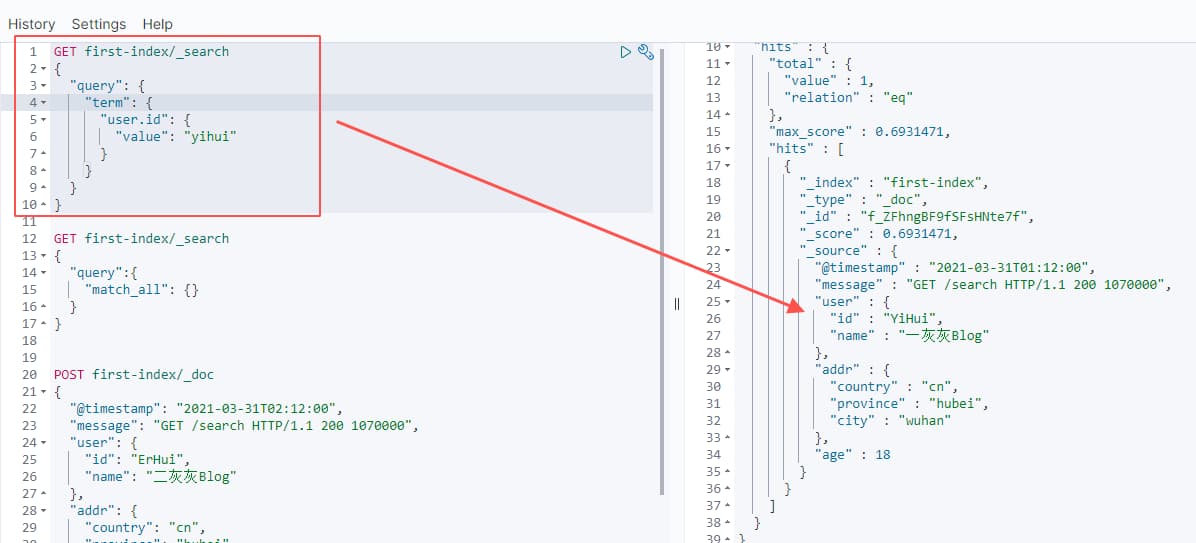
当value不匹配,或者查询的field不存在,则查不到的对应的信息,如
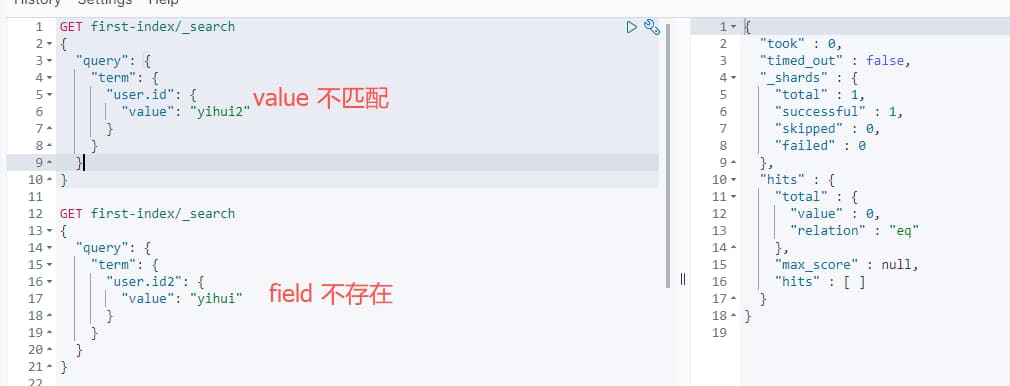
2.3 terms 多值匹配
term表示value的精确匹配,如果我希望类似value in (xxx)的查询,则可以使用terms
语法:
1 | { |
实例如
1 | GET first-index/_search |
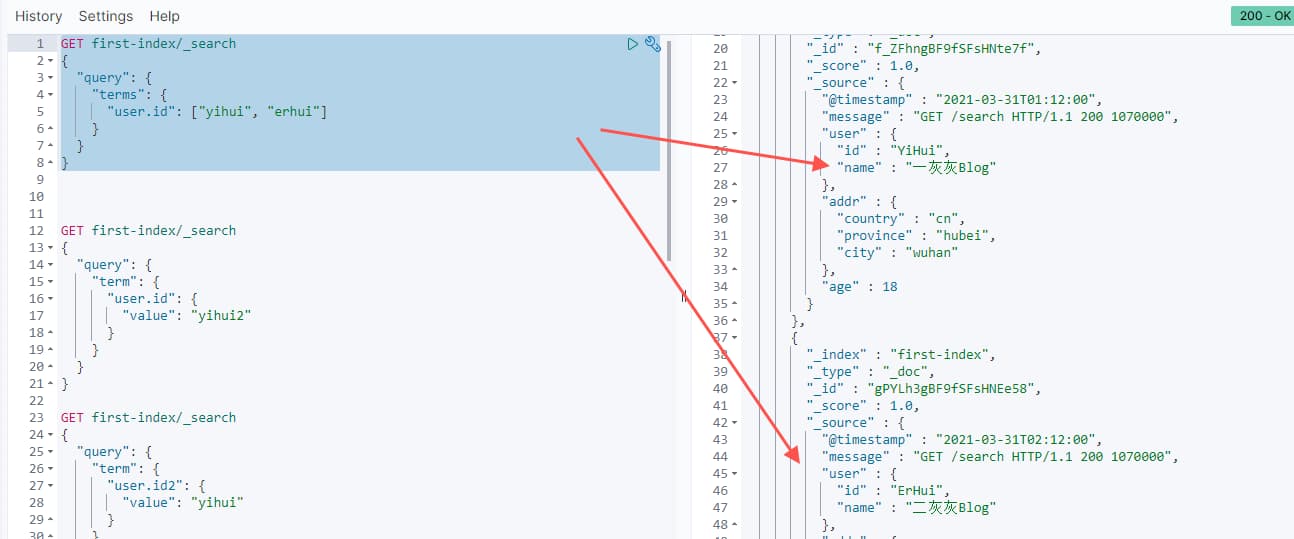
2.4 range 范围匹配
适用于数值、日期的比较查询,如常见的 >, >=, <, <=
查询语法
1 | { |
| 范围操作符 | 说明 |
|---|---|
gt |
大于 > |
gte |
大于等于 >= |
lt |
小于 < |
lte |
小于等于 <= |
实例如下
1 | GET first-index/_search |

2.5 字段过滤
根据是否包含某个字段来查询, 主要有两个 exists 表示要求存在, missing表示要求不存在
查询语法
1 | { |
实例如下
1 | GET first-index/_search |
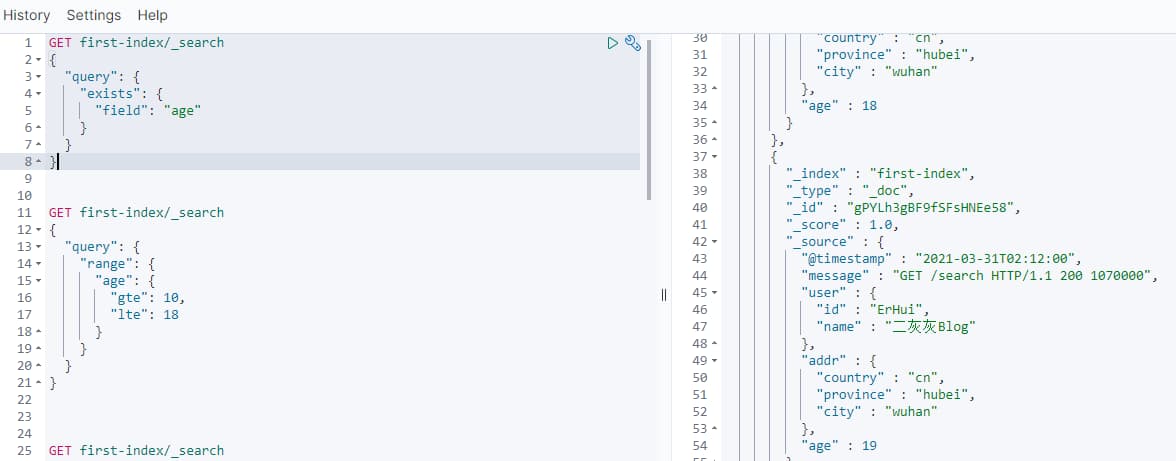
2.6 组合查询
上面都是单个查询条件,单我们需要多个查询条件组合使用时,可以使用bool + must/must_not/should来实现
查询语法
1 | { |
实例如下
1 | ## user.id = yihui and age < 20 |
下面截图以 must_not 输出示意
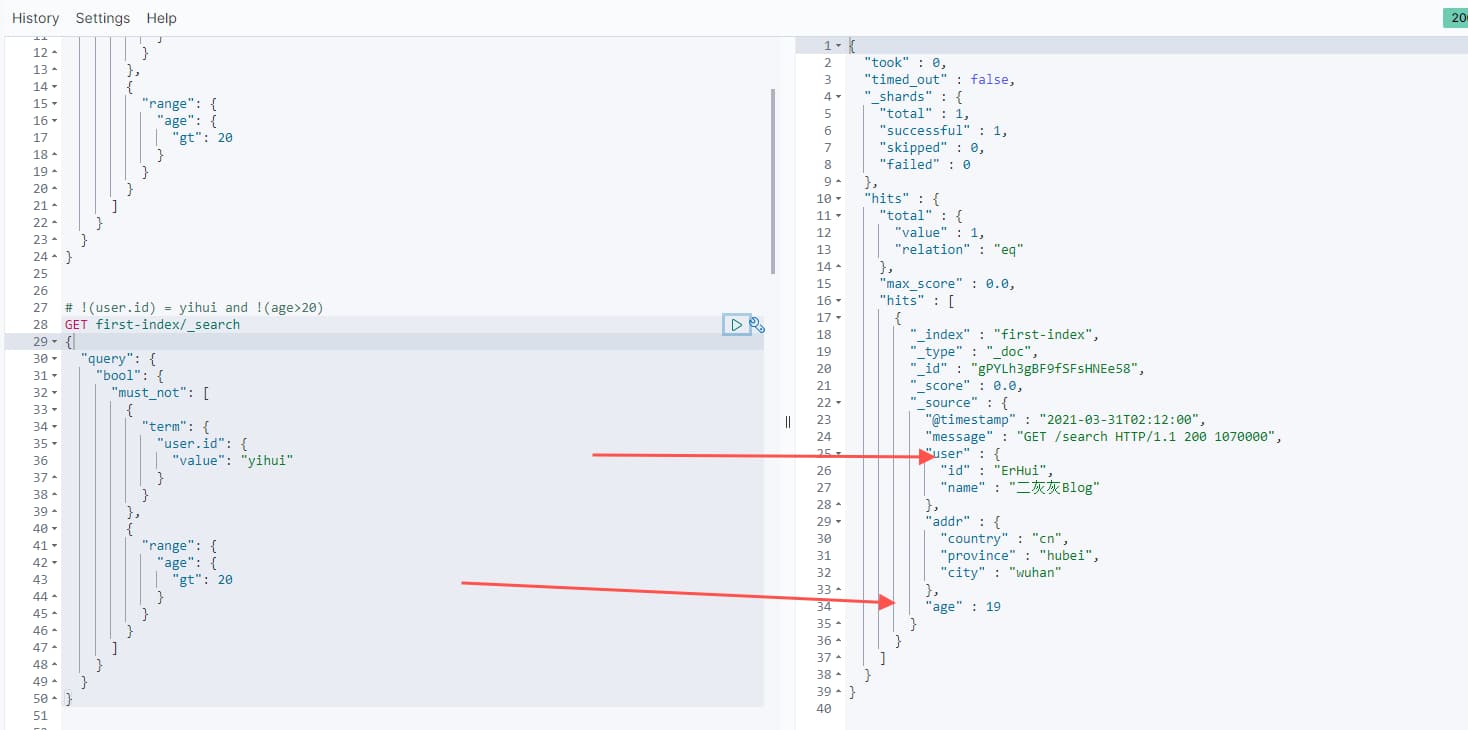
说明
- 前面根据字段查询
existing只能单个匹配,可以借助这里的组合来实现多个的判断
2.7 match查询
最大的特点是它更适用于模糊查询,比如查询某个field中的字段匹配
语法
1 | { |
举例说明
1 | GET first-index/_search |
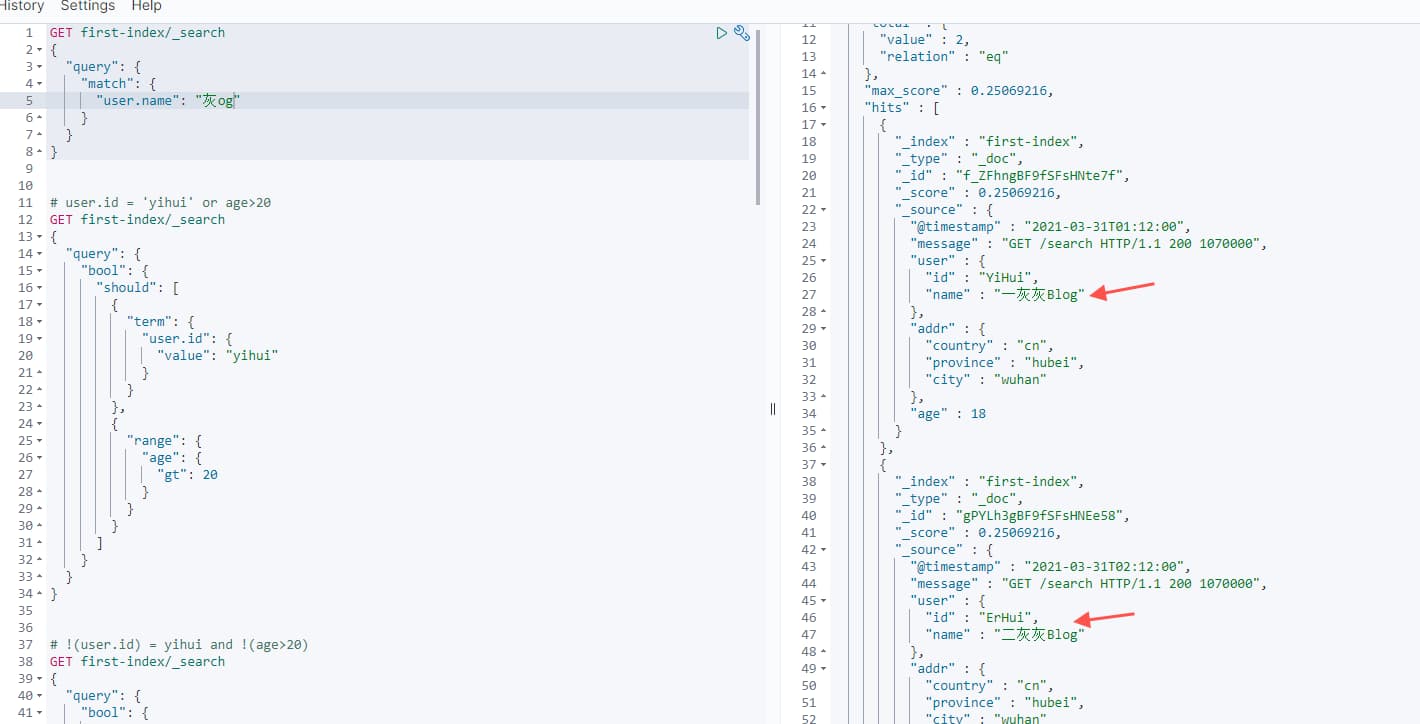
说明,如果有精确查询的需求,使用前面的term,可以缓存结果
2.8 multi_match查询
更多相关信息,可以查看: 官网-multi_match查询
多个字段中进行查询
语法
- type:
best_fields、most_fields和cross_fields(最佳字段、多数字段、跨字段) - 最佳字段 :当搜索词语具体概念的时候,比如 “brown fox” ,词组比各自独立的单词更有意义
- 多数字段:为了对相关度进行微调,常用的一个技术就是将相同的数据索引到不同的字段,它们各自具有独立的分析链。
- 混合字段:对于某些实体,我们需要在多个字段中确定其信息,单个字段都只能作为整体的一部分
1 | { |
实例演示
1 | GET first-index/_search |
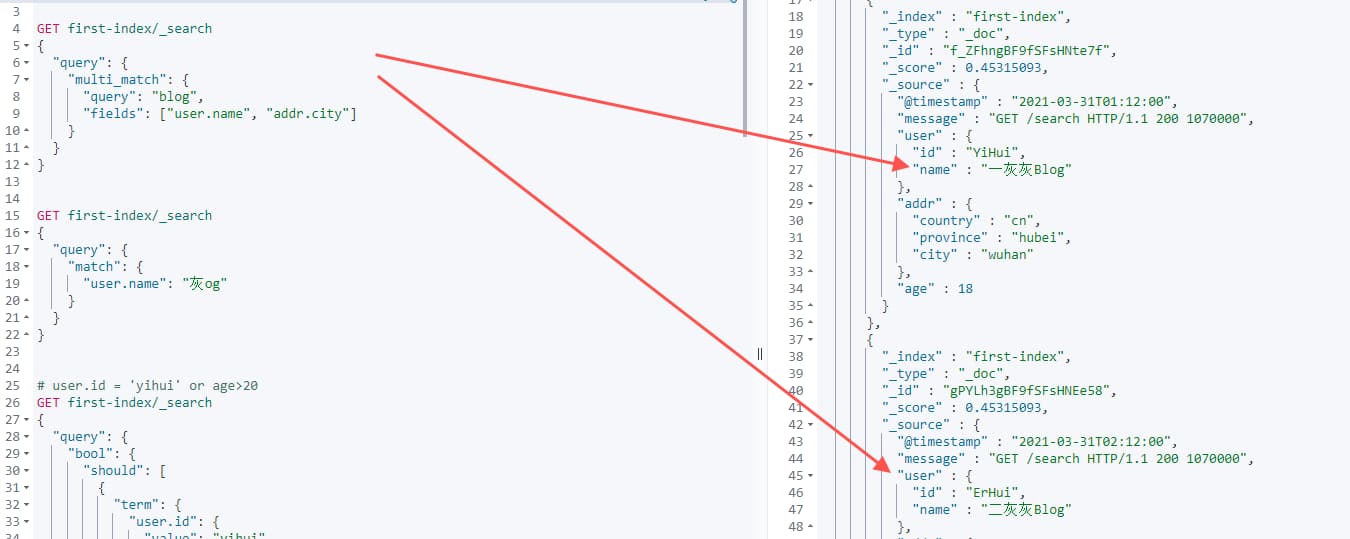
上面除了写上精确的字段之外,还支持模糊匹配,比如所有字段中进行匹配
1 | GET first-index/_search |
2.9 wildcard查询
shell统配符
?: 0/1个字符*: 0/n个字符
1 | GET first-index/_search |
说明,对中文可能有问题
2.10 regexp查询
正则匹配
1 | GET first-index/_search |
2.11 prefix查询
前缀匹配
1 | GET first-index/_search |
2.12 排序
查询结果排序,根据sort来指定
1 | { |
实例如下
1 | GET first-index/_search |
2.13 更多
更多操作姿势,可以在官方文档上获取
3. 删除文档
需要根据文档id进行指定删除
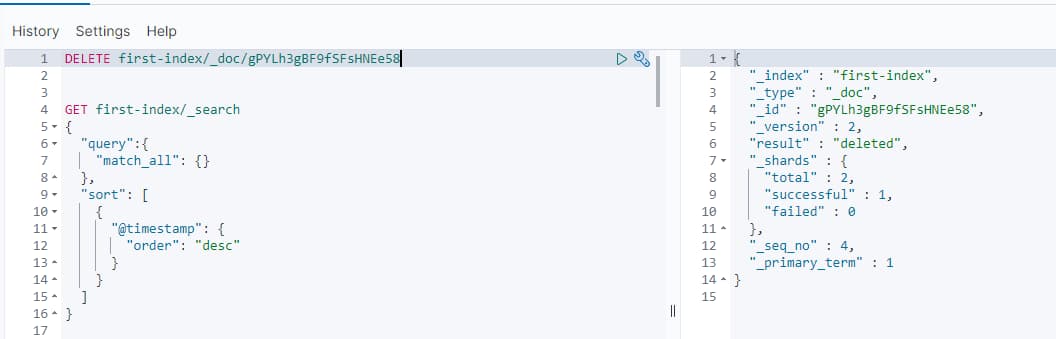
1 | DELETE first-index/_doc/gPYLh3gBF9fSFsHNEe58 |
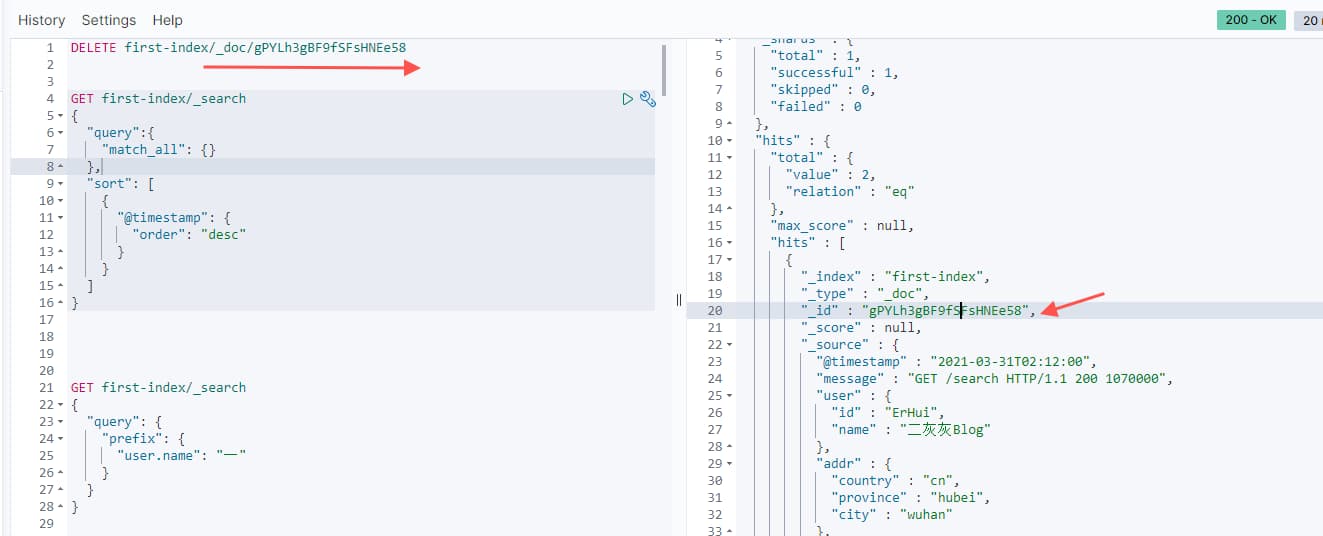
删除成功
4.更新文档
4.1 覆盖更新
使用PUT来实现更新,同样通过id进行
- 覆盖更新
- version版本会+1
- 如果id对应的文档不存在,则新增
1 | PUT first-index/_doc/f_ZFhngBF9fSFsHNte7f |

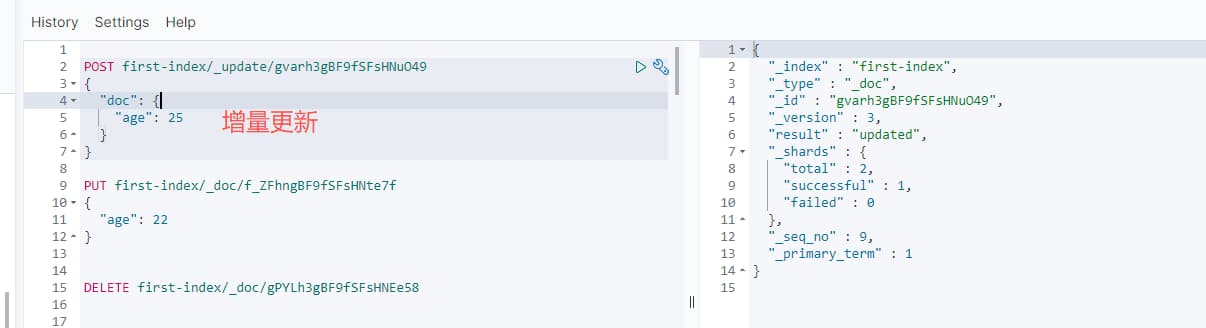
4.2 增量更新
采用POST来实现增量更新
- field 存在,则更新
- field不存在,则新增
1 | POST first-index/_update/gvarh3gBF9fSFsHNuO49 |
此外还可以采用script脚本更新
- 在原来的age基础上 + 5
1 | POST first-index/_update/gvarh3gBF9fSFsHNuO49 |
II. 其他
1. 一灰灰Blog: https://liuyueyi.github.io/hexblog
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
3. 扫描关注
一灰灰blog


