使用Prometheus进行采样收集,借助Grafana进行大盘展示,可以说是系统监控层面的基本操作了,在grafana的大盘配置时,借助变量的灵活性,来展示不同维度的数据表盘比较常见
现在有这样一个场景,一个应用有多台机器,我们设置一个变量 instance 来表示具体的实例ip,支持通过ip来选择不同机器的监控,怎么操作?
1.变量配置
要实现上面这个case,第一步就是设置一个变量

注意上面的变量配置,label_values(instance) 获取的是所有的实例ip,然而一般的情况下,我们需要针对应用维度进行区分,比如每个上报的metric,都包含application,现在我只希望查看prometheus-example应用的相关信息
测试变量配置可以如下
1 | label_values(http_server_requests_seconds_count{application="prometheus-example"}, instance) |
注意http_server_requests_seconds_count 这个属于上报metric name,选一个实际有的即可,接下来配置大盘
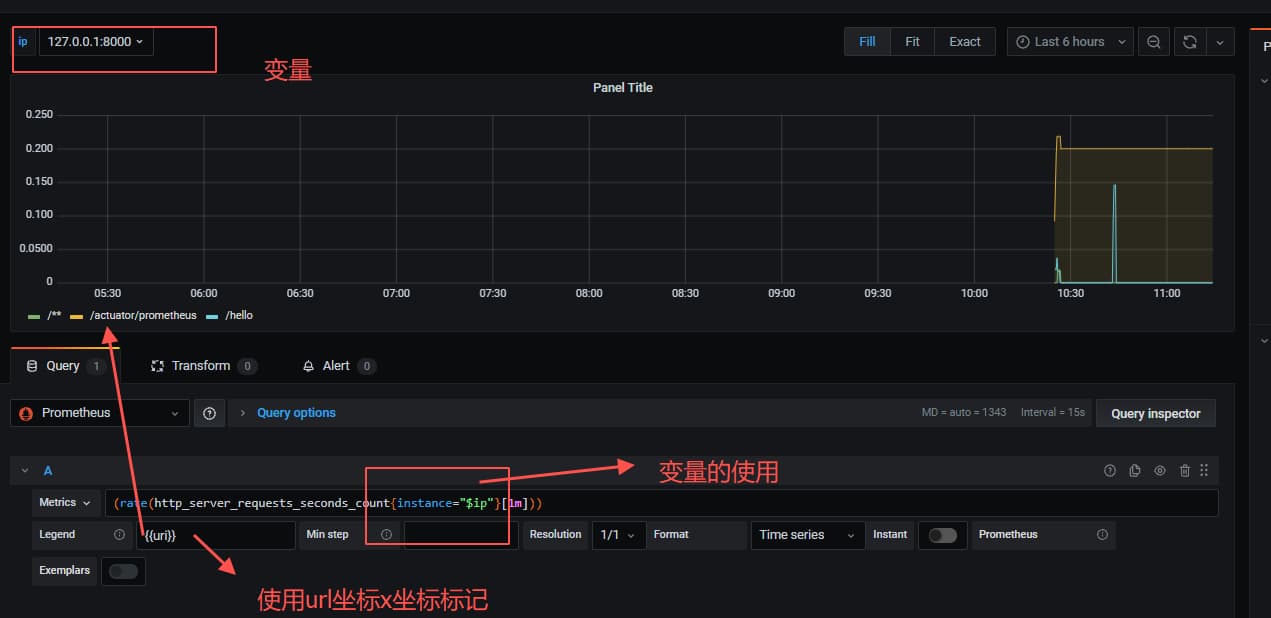
2. include all配置
上面这个完成了一个基本的变量使用配置,但是有这么个问题,如果我想查这个应用所有机器的监控,该怎么办?
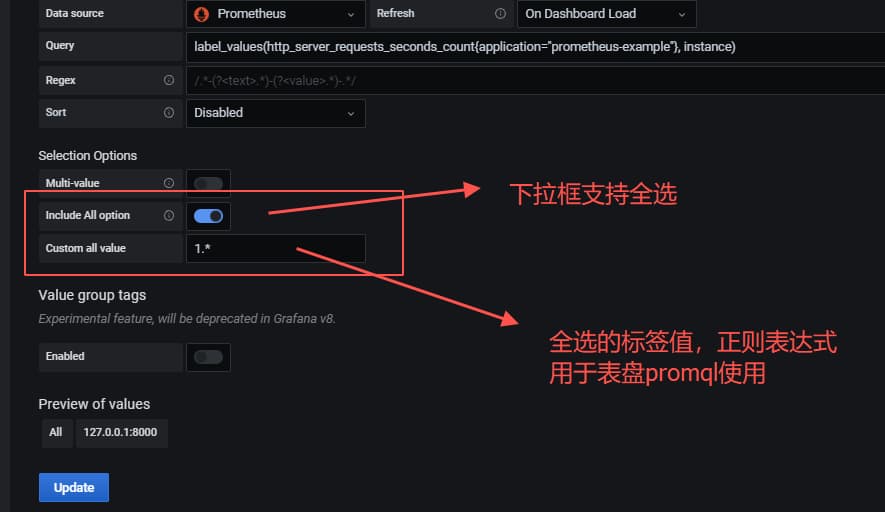
为了支持使用全部,我们的metrics的表达式,就不能使用之前的精确匹配了,需要改成正则方式
1 | (rate(http_server_requests_seconds_count{instance=~"$ip"}[1m])) |
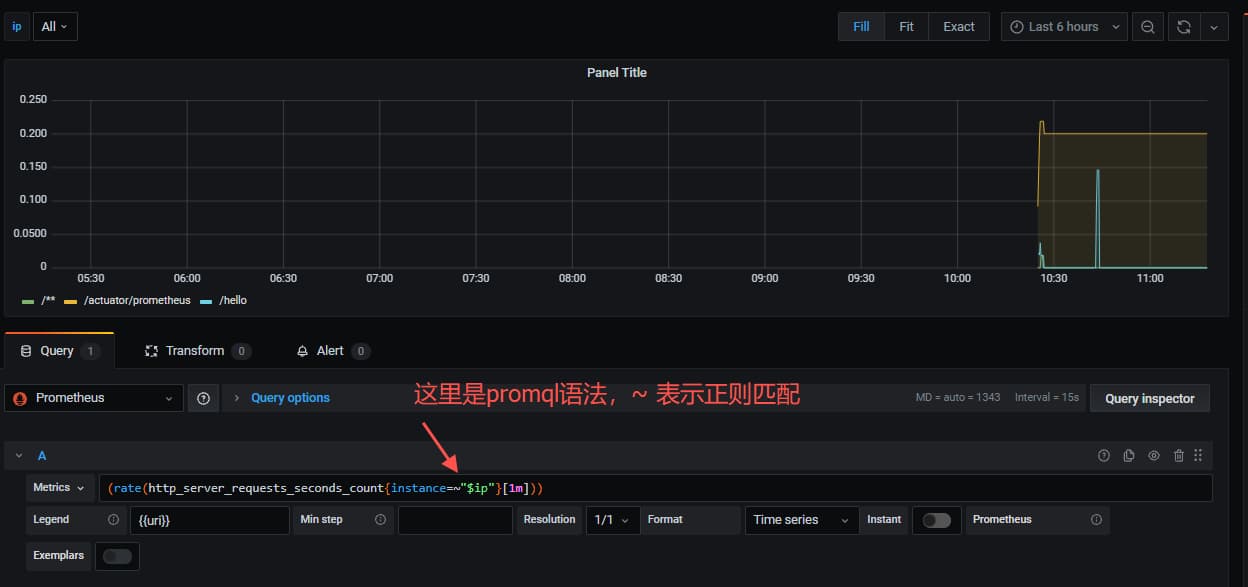
3. 小结
借助Grafana的变量配置来实现大盘的条件筛选,其中变量配置关键点在于
1 | # 获取 'label == 变量名' 的所有label-value |
其次在大盘的metric配置中,对于include all的支持,关键点在于promql的使用
=: 选择与提供的字符串完全相同的标签。!=: 选择与提供的字符串不相同的标签。=~: 选择正则表达式与提供的字符串(或子字符串)相匹配的标签。!~: 选择正则表达式与提供的字符串(或子字符串)不匹配的标签。
II. 其他
1. 一灰灰Blog: https://liuyueyi.github.io/hexblog
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
3. 扫描关注
一灰灰blog


