最近遇到一个统计的需求场景,针对db中的数据,看一下每天的数据量情况,由于DB中时间字段采用的是int存的时间戳,所以最开始想到的是直接对时间进行按天取整,然后再Group统计数据;
除此之外,使用DATE_FORMAT函数来处理可能是更简洁的方法了,下面分别介绍下两种方式
1. 时间取整方式
假设现在有一个user表,其中create_time 为 int类型的时间戳,此时我们需要统计每天的新增用户数,第一种方式就是将create_time转换为天为单位的整数,然后group分组之后计数即可
对应的sql如下
1 | select floor(create_time / 86400) as c, count(*) from `user` group by c |
使用上面这种方式虽然可以统计出结果,但是显示并不友好,如上面这个c实际上是距离标准起始时间过去的天数;无法直观看到每天的数量情况
2. data_format方式
接下来再介绍一下根据日期格式化这个函数来实现数据统计
函数说明
这个函数通常接收两个参数,使用姿势形如
1 | DATE_FORMAT(date,format) |
- date: 日期
- format: 规定日期/时间的输出格式
注意上面的date,要求是日期格式,可我们现在的数据是int类型,怎么整?
先通过from_unixtime函数来转换为日期,然后再使用data_format来格式化分组,这样就可行了
比如按天统计的sql可以如下
1 | select date_format(from_unixtime(create_time), '%Y-%m-%d') today, count(*) as cnt from user group by today |
返回结果形如
| today | cnt |
|---|---|
| 2022-07-02 | 6 |
| 2022-07-03 | 4 |
| 2022-07-04 | 4 |
| 2022-07-05 | 3 |
| 2022-07-06 | 2 |
| 2022-07-07 | 1 |
如果需要按周统计,也很方便,将format改成 %Y-%u
1 | select date_format(from_unixtime(create_time), '%Y-%u') today, count(*) as cnt from user group by today |
返回结果形如
| today | cnt |
|---|---|
| 2022-22 | 27 |
| 2022-23 | 52 |
| 2022-24 | 28 |
| 2022-25 | 33 |
| 2022-26 | 39 |
| 2022-27 | 10 |
同样按年统计,则将format改成%Y即可
下面给出format对应的取值说明
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T 时间 | 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w 周的天 (0=星期日 | 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
日期不连续场景补充说明
评论大佬指出上面这种统计方式有一个缺陷,当某一天没有数据时,会导致统计出来的数据不连续,简单来讲,现在8.1号3号有数据,但是2号没有数据,则统计出来的形如
1 | 2022-08-01 10 |
那么我们能实现缺的日期自动补零么?
下面给一个供大家参考的方法
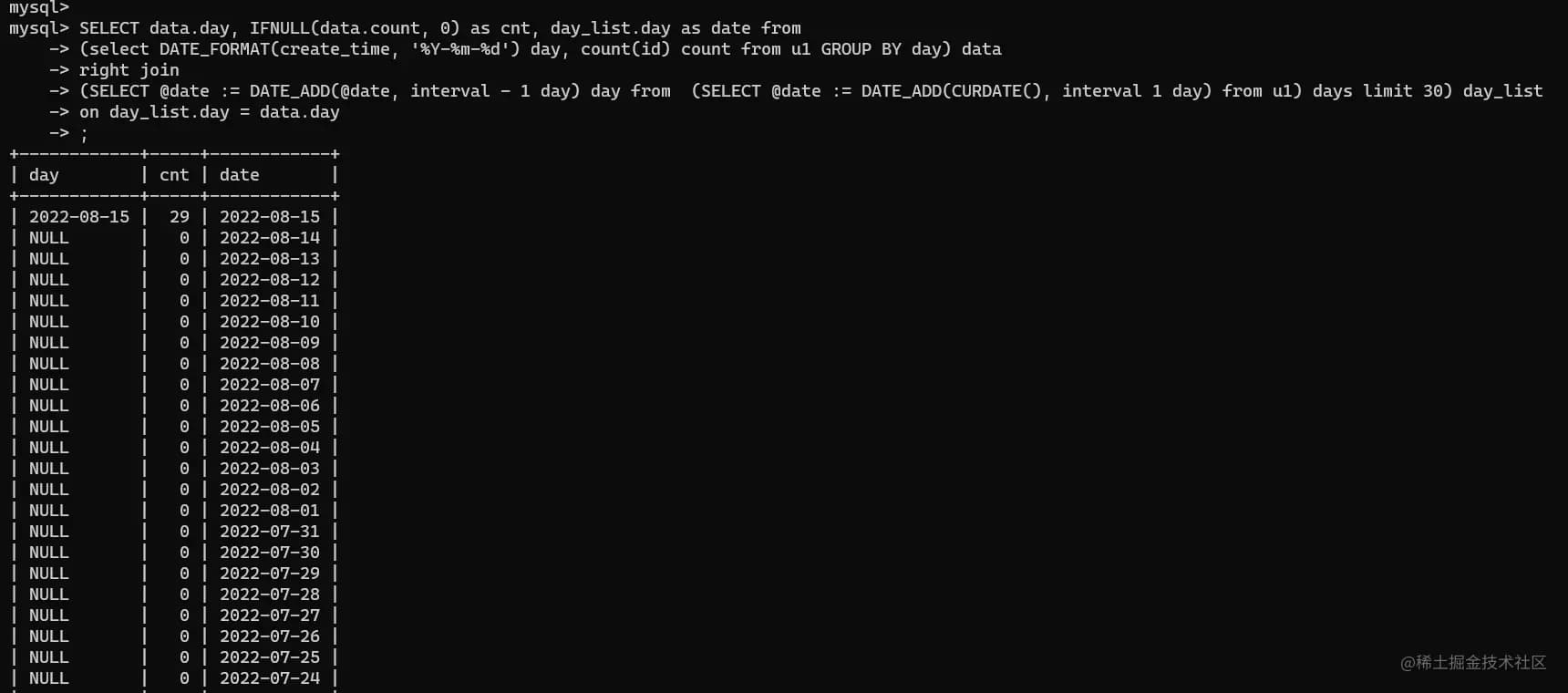
1 | SELECT data.day, IFNULL(data.count, 0) as cnt, day_list.day as date from |
上面这个sql分了两部分,先看后面这一部分
1 | -- 下面这个主要是构建一个日期表day_list, 只有一个成员 day, 取值为今天,昨天,前天,一直往前; 要求 u1 这个表的数据超过30条 |
其中u1是一个数据行数超过30的表,执行之后实际输出如下
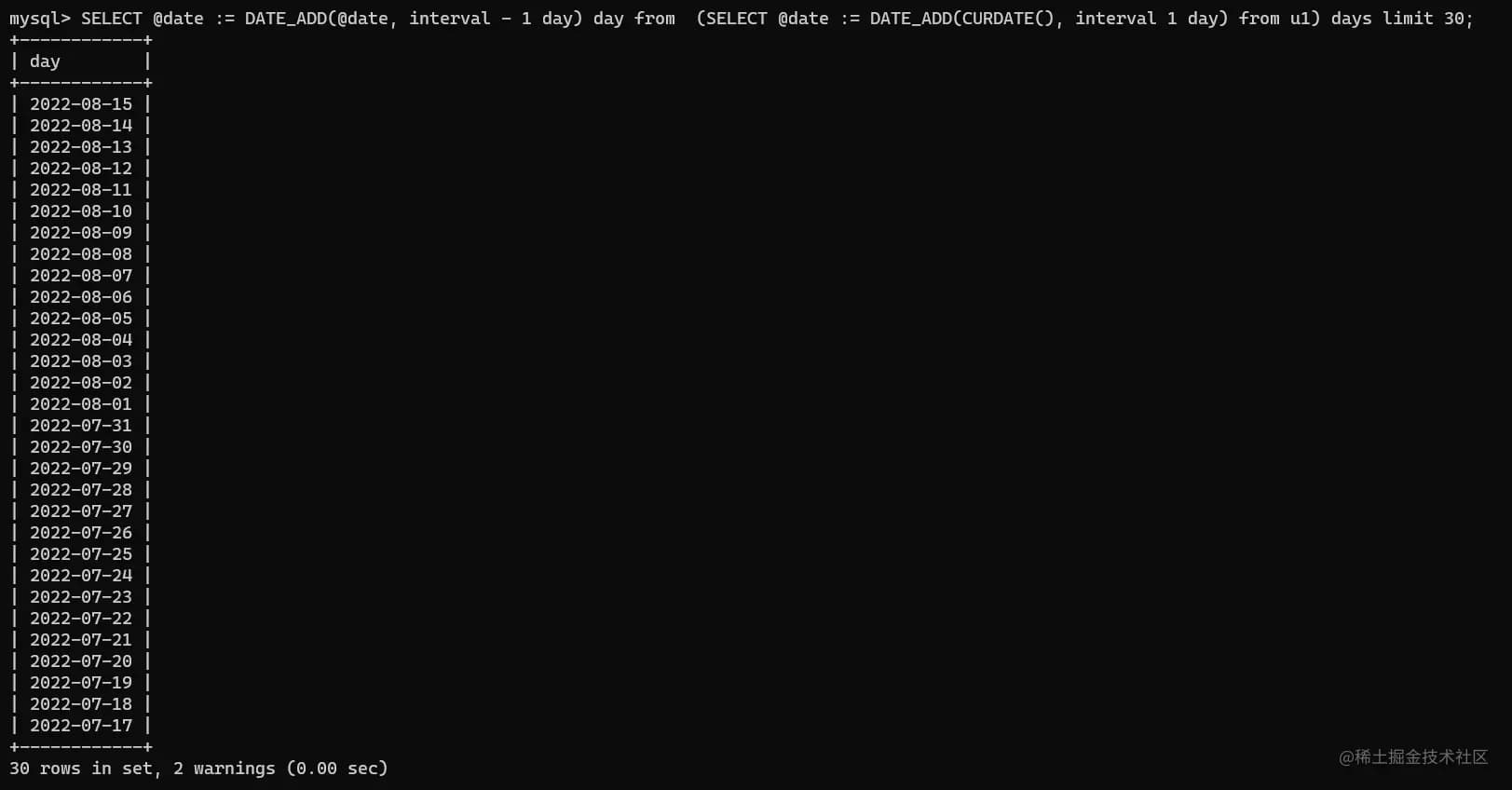
前面的部分则是我们上面介绍的数据统计
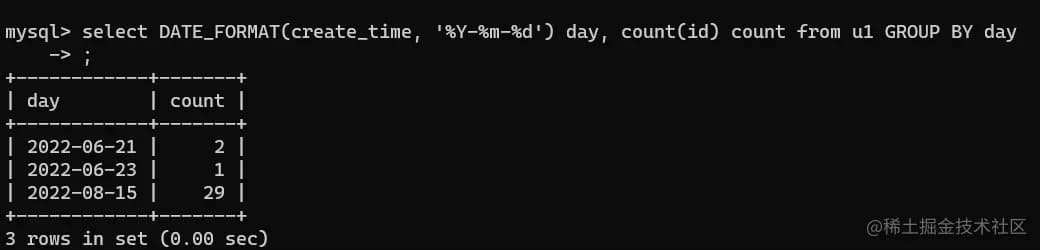
1 | -- 下面这个则是统计sql,将其余日期表进行关联 |
两个表join之后,对于null的数据自动补0,所以结果如下
一灰灰的联系方式
尽信书则不如无书,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 个人站点:https://blog.hhui.top
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
- 微信公众号:一灰灰blog


